高质量数据是智能客服好用的前提
AI 领域重要人物,美国斯坦福大学教授, Google Brain创建者吴恩达曾经 说过,如果大模型和AI应用能够成功,80%依赖高质量的数据。
根据2024年4月15日斯坦福大学发布的2024年度《人工智能指数报告》,过 去一年,以ChatGPT为代表的人工智能模型席卷世界,生成式人工智能的领域资 金比2022年增长了近八倍,达到252亿美元。在图像分类、视觉识别和语言理解 等领域,人工智能已经超越了人类的能力。然而,在数学竞赛、视觉理解和规 划等更复杂的任务上,人工智能仍在追赶人类。在中国也是如此,以金融行业 为例,在国内42家上市银行中,已经有9家银行在2023年半年报中明确提及正在 探索大模型应用。目前在国家互联网信息办公室登记备案,提供生成式智能服 务的企业已达到117家,相信伴随生成式人工智能的发展,在客服行业也必将迎 来一次智能客服的升级与重构。
回顾历史,10年前,当智能客服刚刚兴起的时候,我们也曾看到过上百家 企业一哄而上提供智能客服服务的场景,今天回头再看,能留存下来的企业凤 毛麟角,虽然过去10年企业在智能客服上投入了大量的资金,但从效果来看, 整个社会对智能客服的反馈仍然是矛盾和撕裂的。一方面,有人认为智能客服 的出现,把客户服务延伸到了所有和客户交互的触点,在工作效率提升、运营 成本降低、服务质量增强、个性化服务和数据分析优化上带来了显著的效益; 另一方面,因为智能化程度有限、数据处理不到位、应用体验设计不够友好等 问题,造成各大央媒报道的“人工智能不智能”、“AI客服快把人逼疯了”的 现状。
国内企业在智能客服上做了这么多年的投入,为什么智能客服还存在这样 或那样的问题呢,笔者认为主要有以下几个原因:一、原有基于NLP(自然语言 处理)技术的人工智能主要属于判别式人工智能的范畴,它根据已知的数据学 习输入和输出之间的关系,从而对未知数据进行预测和分类。它主要关注如何 基于现有数据来做出决策或判断,相对来说,技术应用尚不成熟,使得原有智
能客服在语义理解、个性化服务等方面仍有待提升。例如,一些智能客服难以 识别个性化的提问方式和语句结构,导致无法为用户提供精准化、人性化服 务。这使得智能客服在应对复杂或特殊问题时往往显得力不从心;二、一些企 业为了降低成本和提高效率,过度使用智能客服,没有友好转接人工客服的流 程,当智能客服无法应对某些问题时,客户往往无法获得及时有效的帮助,导 致客户体验下降;三、智能客服能否发挥作用,数据质量问题是一个重要的瓶 颈,由于智能客服数据来源的多样性和复杂性,数据中可能存在噪声、冗余和 不一致等问题,这会影响到智能客服的准确性和效果。同时,在使用智能客服 时,数据采集、清洗、预处理和标注是一个长期工作,很多企业往往只在项目 上线初期,为了保证智能客服的准确率,花费大量的精力进行数据处理,一旦 上线,没有专门的预算和人员持续地完成数据处理工作,导致智能客服无法得 到加工过的数据,最后的结果必然不尽人意。
随着生成式人工智能在全球的兴起,智能客服这三方面问题,有望通过大 模型与NLP技术结合的方式获得改善或解决。首先,大模型时代的智能客服机器 人拥有更强大的语义理解、处理复杂对话流程,情感分析和情绪识别、自主学 习和持续改进的能力。这得益于大模型从大量数据中学习到的丰富知识,使其 能够更深入地理解客户的意图,并在各种场景中自如地与客户对话。这种理解 能力超越了传统NLP技术所能提供的范围,使智能客服能够提供更精确、更个性 化的服务。其次,伴随智能客服应用的普及,开始有一大批企业,开始重视应 用体验设计,让智能客服与人工服务之间的切换更加自然、高效和顺畅,以满 足客户不断变化的需求。当客户的问题超出智能客服的处理范围或需要更深入 的解答时,智能客服能够自动识别并引导客户转向人工服务,这是一种技术手 段,更是一种设计思维。最后,在大模型时代,“高质量数据是智能客服好用 的前提”这一观念,已经成为行业共识。大模型基座公司,购买了大量的数据 训练自己模型,在针对企业客户时,往往采用检索增强生成(RAG),微调和标 注等方法,让数据变得更准确,给客户的回答更专业。通过数据采集的泛化处 理、数据标注和模型评估及内容的改写,希望让大模型可以理解,让企业用户 更加放心使用。
智能客服的核心是机器学习模型,这些模型必须通过大量的数据训练来学 习如何理解客户的问题,并给出相应的回答。如果数据包含错误、不完整或不 一致的信息,模型的学习效果将大打折扣,可能导致误解客户意图或给出错误 的回答。通过对高质量数据的分析,智能客服可以不断优化对话流程,提高响 应速度和处理效率。在智能客服中,数据处理是一个核心环节,涉及多个关键 步骤以确保数据的准确性和有效性,从而支持高质量的客户服务。数据处理基 本包括以下几个方面,
1.数据收集:这是智能客服数据处理的起点,主要收集客户服务数据,包 括客户的问题、客服的回答、客户的反馈等。这些数据将用于后续的模 型训练和优化;
2.数据清洗:清洗数据是确保数据质量的关键步骤。主要目的是去除数据 中的噪声、异常值和重复项,纠正错误,保证数据的准确性和一致性。 清洗过程可能包括去除无关信息、处理缺失值、标准化数据格式等;
3.数据预处理:预处理是为了将数据转化为适合机器学习模型训练的形 式。这包括分词、去除停用词、标注等操作,以便于AI模型的理解和识 别,预处理还可以包括特征提取和选择,为模型提供有意义的输入;
4.数据分析和挖掘:通过统计分析和机器学习等方法,挖掘数据中的规律 和趋势,这有助于智能客服更好地理解客户的需求和行为,提升服务的 针对性和有效性;
5.模型训练:使用清洗和预处理后的数据来训练AI模型。目标是使模型能 够准确理解客户的问题,并给出合适的回答。训练过程可能涉及调整模 型参数、优化模型结构等,以达到最佳性能;
6.模型评估和优化:训练好的模型需要进行评估,以验证其性能。根据评 估结果,对模型进行必要的优化,以提高其准确性和响应速度;
7.数据应用:将数据分析的结果和训练好的模型应用到实际工作中,如客 户服务、产品推荐等。这有助于提供更个性化和高质量的服务,提升客 户的满意度和忠诚度。
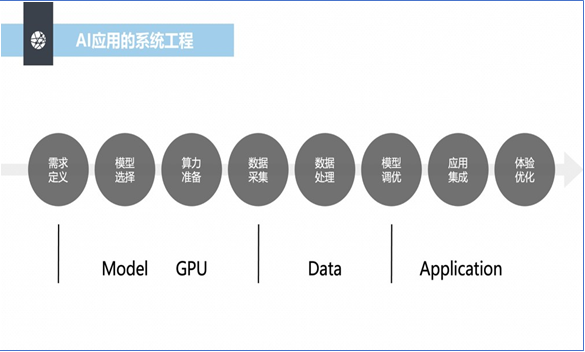
图1.大模型时代智能客服系统工程模块
我们意识到在大模型时代,如果使用智能客服,数据处理是如此重要,但 很有意思的是,如果我们把智能客服当成一个系统工程,我们会发现,从需求 定义、模型选择、算力准备、数据采集、数据处理、模型调优、应用集成到体 验优化等不同模块,都有不同的服务商在支撑和推动智能客服的发展。比如当 我们看到模型选择时,我们可以想起一批大模型基座的厂商;当我们看到算力 准备模块时,让我们可以想起一批算力服务商和云服务商;当我们看到应用集 成和体验优化模块时,让我们可以想起很多集成商和原来的AI服务商,但是当 我们看到数据采集、数据处理和模型调优模块时,我们一方面想不出在我们这 个行业哪家数据服务商更专业,另一方面我们往往觉得这个环节,要不是AI厂 商出人做,要不是系统集成商出人做,要不是企业客户自己安排人做,彼此的 边界非常模糊。于是形成了今天两个局面。一个局面是,一些非常优秀的企 业,在智能客服上有很大的投入,他们每年在数据采集和数据处理上几千万, 上亿的投入,让其它企业觉得成本太高,高攀不起;另一个局面是,有一大批 中小企业,把智能客服项目当成一次性买卖的项目,根本没有考虑智能客服上 线后的数据采集和数据处理成本,把这个环节交给系统集成商或者AI厂商,往 往是项目验收前,数据处理得很好,为验收的准确率提供很好的结果,但项目 验收后,在数据处理上没有持续投入的概念。智能客服好用的前提是需要有高 质量的数据,这样的结果就是企业的智能客服越来越不好用,客户也就对原有 提供服务的AI厂商越来越不满。
今天在客服行业我们需要建立一个基本观念,这个观念是,如果企业要想用好大模型和智能客服,前提是拥有高质量的数据,这里数据处理是必须的,而且它是需要持续和付费的,它就像企业交电话费、交短信费一样,在大模型 时代,这是企业必须付出的运营成本。除了大模型基座厂商、大模型算力厂 商、AI应用服务商、系统集成商外,也期望有越来越多,具有数据服务基因的 专业的数据处理服务商进入到客服行业来,客服行业每天都在产生大量的原始 数据,如果能把这些数据变成黄金数据,用黄金数据训练形成行业模型,最终 让智能客服更好用,这也算推动行业高质量发展的新动力。
作者李农,中国通信企业增值服务专业委员会评定中心常务副主任。
本文刊载于《客户世界》文集2024第二辑•战略与创新。
转载请注明来源:高质量数据是智能客服好用的前提
panjl
《客户世界》杂志编辑。有关投稿,呼叫中心企业培训,会议等咨询。可添加编辑潘老师微信:18710108460 或者扫描左边微信二维码进行咨询!

噢!评论已关闭。