“平均”响应时长的误区
随着电商行业、“互联网+”行业的不断发展,开展在线服务的客户服务中心逐渐增多,这一类客户服务中心又称作静默的客户服务中心。与热线服务中心一样,在线服务中心非常关注员工的工作效率,期望在相同资源投入下及时高效地服务更多客户。
在线服务中客户与座席双方通过文字进行交流,客户每发出一条文字必然希望能够得到及时有效的回应,所以在线服务中有一个广泛使用的效能考核指标叫做平均响应时长,它反映的是座席员是否总是能够及时响应客户问询。平均响应时长的计算依据是座席与客户的多回合聊天记录,首先依据座席每一句聊天内容的抵达时间计算出这一句话的响应时长,进而将全部聊天内容的响应时长加总计算,得出全天、全月的平均响应时长。
响应时长一“平均”,问题就来了,它无法真实有效地度量员工的工作表现,因为在线服务往往是一对多的,而同时服务客户的多寡必然会显著影响平均响应时长,当并发客户量较小时1v1的专属服务好比亲密爱人聊天,总是能够非常迅速地响应客户问询;但当客户并发量较大如1v4甚至1v6时座席员无法在第一时间响应所有客户,平均响应时长自然拉长。
对于不区分客户并发量的平均响应时长来说与其说是在考量员工的响应速度,不如说是在评价服务场景的异同,即到底是1v1专属服务的时长多一些还是1v4密集服务的时长多一些。
可以拿不同种类的外呼业务管理进行一个类比,假设某客户服务中心只进行两种业务,分别是盈利创收的营销推荐业务、不产生经济利益的服务回访业务,那么该中心会使用相同一套指标管理两种不同的业务(比如两者的综合平均通话时长、综合客户回电率)么?答案是否定的,一定是将两种业务分开管理。
不同种类的外呼业务分拆管理是因为外呼业务的发起方是客户服务中心,从外呼的数据源、执行团队等方方面面都可以完全进行分拆,在管理上有可操作性,但对于在线服务业务来说众多座席在一个共享队列中进行服务,而且大部分在线系统报表都无法直接提供依照并发量分拆的考核指标,除非重新规划、设计算法,否则难以得到依照客户并发量分拆的考核指标,这就造成很多客户服务中心只能退而求其,使用混合各种业务并发量的“平均”指标数据进行管理,但与外呼业务管理类似,如果认定1v1专属服务与1v4密集服务是不同的服务形态,通过对在线业务数据进行一系列加工处理,进而将响应时长、客户静默比例、客户服务满意度、成单转化率等一系列的在线服务指标依照客户并发量区分来看,一定可以发现一片蓝海。比如可以检验客户并发量达到多少时客户服务满意度、成单转化率等关键指标出现显著下滑,并据此制定客户并发量的管理目标;还可以检查每名座席在不同并发量下的业务表现,选取在较低并发量时服务质量极佳的员工从事VIP或高收益岗位,选取在较高并发量时服务效率极佳的员工从事一线客户服务工作。
在数据驱动力系列连载中坚持从底层系统进行数据获取、存储和加工利用,坚持在EXCEL层面即实现复杂的数据运算,坚持从运营管理角度进行数据分析应用,方便各家客户服务中心应用推广,所以接下来重点介绍如何在EXCEL表格中分拆在线服务的系列指标。
图1在线服务后台数据记录格式

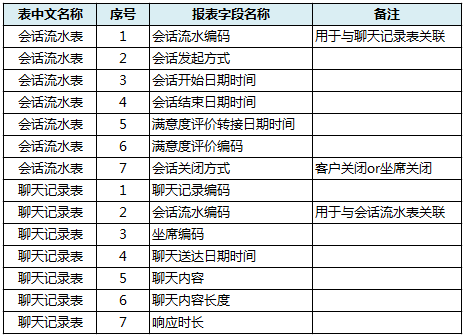
在介绍指标计算方法之前首先要了解在线服务系统的后台数据基础。几乎所有在线业务系统都有会话流水表、聊天记录表两张数据表,其中会话流水表记录了座席与客户发生会话的开始时间、结束时间等会话层有关信息;聊天记录表则记录了每一次座席或者客户输入的聊天内容、聊天发生时间等。
两张数据表的数据定义大致如图1所示,在不同的在线服务系统中可能数据表名称、字段名称略有差异,但一定有类似数据存在。只要找到了对应的数据,就可以按照本文介绍的流程加工出依照并发量分拆的各类数据指。
以平均响应时长的计算为例,计算过程分为以下几步:
1、依照会话流水表中每一次会话的开始时间、结束时间计算出员工在全天每一个时间片段中的并发客户量。
2、计算每一次聊天属于哪个时间片段,进而得出每一次聊天发生时的并发客户量。
3、以并发客户量为维度进行汇总统计。
以上过程中最关键也最困难的是第一步,虽然在会话流水表确实记录了开始时间、结束时间,但会话流水表中的时间记录方式是一条会话对应一行数据,如果有200条会话则对应的有400次会话开始或会话结束,也就有400次并发客户量的数量调整,因此需要把这400个时间点加工整理成399个时间片段,按照全天8小时计算,平均下来每一个时间片段仅有 1.2分钟。
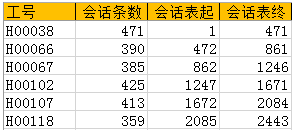
图2会话表计算参数示例
假设一个在线服务中心有200人,每人每天的业务量在200通左右,那么全天就有4万通的会话量,共有8万个时间点,若是直接对8万个时间点进行排序,其计算量非常恐怖,所以在计算时间点排序之前需要先按照员工工号、会话开始时间进行排序,如图2所示计算出每一位员工的会话条数、表格中会话的首条会话位置、末条会话位置等数据以缩减后续计算量。
在明确每一位员工会话的首、末条位置之后就可以在这个范围内进行数据指标的加工计算,从而将排序的数据量级控制下来。在本例中H00038号员工所有的会话开始、结束时间点仅在第1至第471行之间进行运算,H00066号员工的所有会话开始、结束时间点仅在第472至第861行之间进行运算,这种方法把员工的数据依照工号排序,每人只在连续的一段数据区间内计算,好像在计算时为每位员工从一大块奶酪的顶层切下一片奶酪,称作切片计算法。
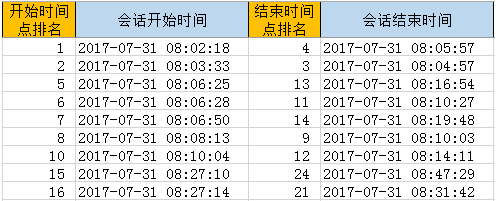
图3会话表时间点排序
使用切片计算法可以在很小的数据区间内进行开始、结束时间点的排序,排序结果如图3所示。接下来可以在一张新的数据表中以时间点排名为依据,每一个时间片段为一行,罗列出每位员工全天各个时间片段的会话并发量。
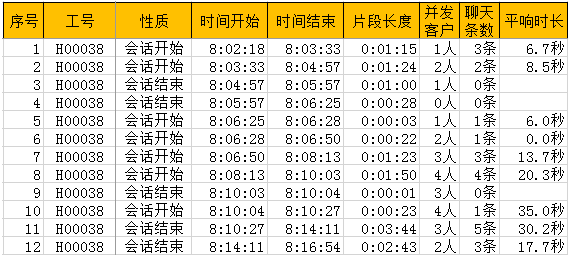
图4员工时间碎片分拆结果
至此,关键的客户并发量分拆已经基本完成了,其结果如图4所示。
之后可以在聊天记录表中使用聊天送达时间为主键,利用Vlookup函数的模糊查找功能就能匹配到每条聊天送达时间所属时间片段对应的并发客户量,进而得出每一个时间片段中的有效聊天条数、平响时长及其他统计数据。需要强调的是在这几步的计算处理中也需要使用前述的切片计算法控制计算量,才有可能通过EXCEL完成庞大的数据运算。
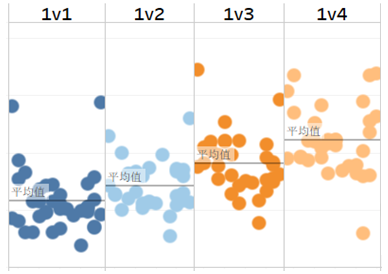
图5根据客户并发量分拆的平响时长
最后,采用Tableau图形分析软件来进行分析结果呈现。这里面每一个数据点代表一位员工,如图5所示,不同客户并发量状态下从1v1至1v4员工的平均响应时长依次放大,说明在不同客户并发量下员工有着完全不同的平响表现区间,但如图所见仍然有一些数据点偏离中心区域,这些数据点是如何产生的、是否存在现场管理的问题,就需要客户服务中心的运营人员开展针对性的分析与管理了。
平均响应时长之外还可以用相同方法对客户静默比例、客户服务满意度、成单转化率等各项关键指标进行分拆与考核,从而体现出忙时抓效能、闲时抓质量的管理思路,进而提升在线客户服务中心综合服务能力。
下期预告:
平均响应时长分拆成1v1至1v4进行统计,那么如何开展后续管理?难道需要为1v1至1v4设定4个考核指标吗?那又如何设定科学合理的指标?数据驱动力第5期将为大家介绍动态目标值管理法,敬请关注。
本文刊载于《客户世界》2017年12月刊;作者肖子京为知名互联网公司客服副总经理。
转载请注明来源:“平均”响应时长的误区
panjl
《客户世界》杂志编辑。有关投稿,呼叫中心企业培训,会议等咨询。可添加编辑潘老师微信:18710108460 或者扫描左边微信二维码进行咨询!

噢!评论已关闭。