基于智能客服的用户日志研究
一、用户日志的定义
在AI(人工智能)行业,“日志”涵盖的范围非常之广。本文所说的“用户日志”,也可以称为userlog,指的是在AI对话机器人上线后,用户与机器人对话所产生的聊天记录,包含用户输入的文本和机器人回复的内容,属于机器训练数据的一种。
二、研究用户日志的意义
研究用户日志具有重要的意义。从机器人训练师的角度来说,对话机器人是为了解答用户疑问而设,而研究用户日志有助于我们理解真实用户问法的特征,从而更好地准备机器训练所需的数据,使得模型训练的效果更好,准确率更高。
三、用户日志的处理方式
在用日志训练机器模型之前,需要对用户日志进行一些预处理,达到较好的训练效果。在这里简要介绍几种较为常见的用户日志处理方式。
1.清洗用户日志:
在这一步骤中,我们需要把一些不利于机器训练的“脏数据”去除。通常需要清洗如下的一些用户日志
1)字数过短的用户日志:根据数据情况不同,“过短”的定义也不同。一般认为3-4字以下的用户日志由于包含的信息量过少,可以批量删除。
2)仅数字或字母的用户日志:这些用户日志通常单独看来也缺乏意义。
3)欢迎语、结束语:例如“您好!”“再见”机器训练不需要这些数据。
4)重复数据:若需要统计次数,先统计后再去重。
5)与业务无关或不合规的数据:和业务不相关的数据需要被清,例如在电商智能客服有用户问到炒股相关的话题。不合规的数据指的是非业务流程内的语句,如粗话、脏话、敏感词等。
2.聚类用户日志:
由于用户日志通常而言数量巨大,为了后期整理数据和训练机器的需要,通常需要借助机器来给用户日志进行聚类,达到批量处理的目的。所谓聚类,指的是按照某个特定标准(如距离准则)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大。常见的聚类方法有K-means,DBSCAN等(此处不做展开),在聚类后我们能获取数个类或簇(cluster),在此基础上再进行下一步的用户日志梳理。
四、用户日志的一些典型特征
根据我们对3个不同行业(金融、物流、电商)各1000多条用户日志的分析,发现如下特征:
1.从句型来看,用户日志以疑问句为主。在不同行业中,用户问的疑问句型都占到了60%以上的比例。
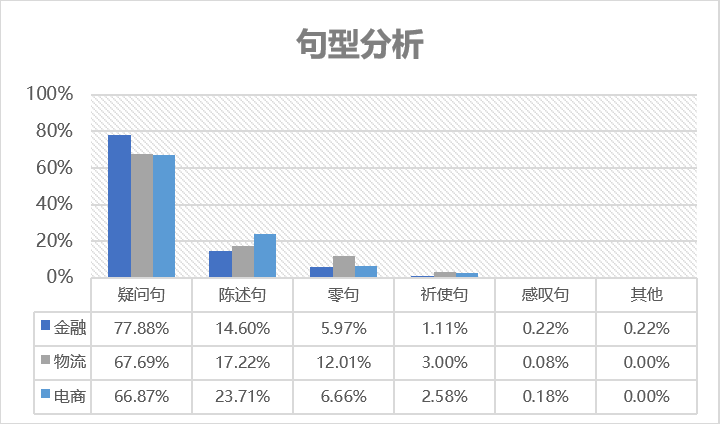
这与对话机器人主要是为了解答用户疑问而设的目的是相一致的。
不过,陈述句也占到了相当的比例,在我们的数据样本中,有约14%-24%左右的用户日志是以陈述句的形式表达。我们观察发现,这部分日志,大多是用户描述自己遇到的一个情况。但由于缺乏明显的提问目的,这类日志相对而言匹配效果欠佳。
例如:是这样的,我的快递原本是到凯里的,我现在人在贵阳,刚好快递也在贵阳,我想在贵阳取算了。
人工分析认为,这条用户日志的目的是将原本寄送到凯里的快递,改派到贵阳。
此外,和人人交互最为不同的是,用户日志中还有一部分比例的零句,即句子成分不完整的名词性或动词性短语。例如:“尺码推荐”就是一个零句。零句通常具有用户目的不明确的特征,给匹配也带来了较大困难,不过这部分句式所占比例不高。
2.不同行业的用户日志有其不同的高频词,通过对三个行业的用户日志进行人工抽取信息点后发现,可归纳总结为行业热门关键词,汇总如下:
物流:人名、时间、地点、单号、手机号码、快递物品、金额、重量、体积、渠道、数量、工具等高频信息点。
电商:手机号码、时间、地点、单号、购买物品、尺码、身高、体重、三围、颜色、金额、数量、渠道等高频信息点。
金融:产品、金额、天数、日期、渠道、数量等高频信息点。
这里值得注意的有两点,一、三个行业都有“金额”、“渠道”、“数量”等信息点;二,物流和电商行业由于部分业务重合度较高,除了上述3个信息点一致,还有手机号码、时间、地点、单号和快递物品/购买物品等5个信息点一致。
3.从单次输入的字数来看,用户的询问主要集中在10-15字的区间。三个行业的平均字数都在13字左右。80%左右的用户日志都在20字以内。
四、用户日志的一些难点案例
目前在机器识别过程中,用户日志给机器带来难点概括起来主要有两种:
1.用户提问时,并不了解整个业务知识库,因此会加入较多冗余的信息,给机器判别造成一定难度。
例如:我三天前买了一件衣服,现在刚收到,衣服质量没什么问题,款式也不错,就是这个尺码实在是太大了,能退吗?
事实上,用户的核心问题在最后一句话,在知识库中对应的问题是“尺码不合适如何退货”,但由于前面的干扰信息过多,可能会给机器匹配带来问题。
2.目前在对话机器人中常用的是单句匹配,效果好效率也高。但实际应用中许多用户会在语境中省略前文提到过的事物,给机器匹配带来一定难度。
例如:可是到现在还没抵扣
这句用户问,我们认为是信息确实。只有查看完整对话,才发现用户上一句说的是“我刷卡之后应该是有刷卡金的”。这种情况下需要把两句话连起来才知道用户想问的是“刷卡金无法抵扣的原因”。
以下,我们会摘取一些用户日志的具体案例来进行分析。
案例1:这个航班儿童也可以购买的吧?因为在其他网站上看到儿童不可定。
在这句用户日志中,前后的关键词“儿童也可以购买”和“儿童不可定”实际上是意义相反的,这会给机器学习条件下的识别有一定的难度。但结合整句话的句意,可以判断关联词“因为”后面的为次要内容,主要内容在第一句话,由此可以判断用户目的是想询问此航班儿童是否可以购买。
案例2:是这样的,我的快递原本是到凯里的,我现在人在贵阳,刚好快递也在贵阳,我想在贵阳取算了。
在这个案例中,用户采用了陈述句的句式来描述自己遇到的情况。句中一共出现了4次地名,其中后3次所指的是同一个地方。
通过人工分析句意发现,用户的目的是,想把原来寄到凯里的快递改派到贵阳,即想知道“如何修改收件地址”。而这些关键词却从没出现在这句话中,因此也给机器学习的准确识别带来一定的难度。
案例3:运单显示今晚20:00送达,20:00我们下班了,最好下午17:00送到。
这个案例依旧是采用陈述句的句式,出现了3次时间点。其中前两次是同一个时间点。跟上一个案例不同的是,为了理解用户目的,机器除了需要知道第三个时间点不同于前两个,还需要知道17:00这个时间早于20:00,用户想问的是“能否提前派件”。
五、提升用户意图识别率的一些方法
提升用户意图识别率有数据端和算法端两种方式。从数据端而言,为了使对话机器人上线后达到比较好的识别效果,保证关键指标,在数据准备时,若无法获取到用户日志,则可以多模拟真实用户问的问法来进行扩写,从句型、句式、字数、高频信息点等方面做到和用户日志相近。从算法端而言,可以加入命名实体识别(NER)的技术,或从所占比例较高的用户日志特征入手,进行定制化的模块算法优化,此处不做展开。
本文刊载于《客户世界》2019年3月刊;作者焦雯娜为竹间智能科技(上海)有限公司人工智能训练师。
转载请注明来源:基于智能客服的用户日志研究
客户世界
这家伙很懒,什么都没写!

噢!评论已关闭。