认知计算下的智能客服——基于IBM Watson的应用研究
随着大数据时代的发展,企业已经不再满足于传统的自动应答服务作为人工客服的一种补充,转而寻求更为高效智能的智能客服,如淘宝的小蜜或券商们正在努力发展的智能投顾。目前通过远程服务调用为企业客服提供如语音与文本转换、情绪分析、本体建模、实体识别和语义推理等核心智能化技术服务正在成为一种主流趋势,如腾讯发布了微金小云客服 (Intelligent Customer Service),其目标是依托智能分析识别引擎、结合大数据深度学习和训练来打造智能机器人,助力企业为其用户提供智能、高效的客服服务。这些平台的出现让我们看到了智能客服正在逐渐走入日常的工作和生活中,但与大数据和深度学习不同的是IBM提出了基于认知计算的智能系统并发布了世界上第一个认知计算平台Watson。认知计算源自模拟人脑的认知功能,传统的计算技术是定量的,并着重于精度和序列等级,而认知计算则试图解决生物系统中的不精确、不确定和部分真实的问题。这一平台利用语义分析、自然语言处理和机器学习为全世界开发者提供接入服务。2011年2月,Watson在智力节目《危险边缘》上打败了人类对手,用自然语言实现问答,展示了其强大的学习能力,自那个时候开始,Watson成为国际主流的认知计算平台,本文在基于Watson平台提供的应用接口(API)的基础上进行智能客服的实证研究。
一、认知计算与Watson
1、认知计算
认知计算是基于认知科学的基础上提出的。认知科学认为人类对事物的认知往往是从一个“不知”到“了解”再到“理解”的过程,人脑接受外界输入的信息经过头脑的加工处理转换成内在的心理活动,再进而支配人的行为,这一过程就是信息加工的过程,也就是认知过程。简而言之,认知科学是研究人类感知和思维对信息处理过程的科学,包括从感觉的输入到复杂问题的求解,从人类个体到人类社会的智能活动,以及人类智能和机器智能的性质,它是现代心理学、信息科学、神经科学、数学、科学语言学、人类学乃至自然哲学等学科交叉发展的结果。对于认知计算源自模拟人脑的认知功能,研究人员自90年代开始用认知计算一词来表明该学科用于教计算机像人脑一样思考,而不只是开发一种人工系统。传统的计算技术是定量的,并着重于精度和序列等级;认知计算则试图解决生物系统中的不精确、不确定和部分真实的问题,以实现不同程度的感知、记忆、学习、语言、思维和问题解决等过程。从历史上看,认知计算是第三个计算时代:第一个时代是制表时代(Tabulating Computing),始于19 世纪,进步标志是能够执行详细的人口普查并支持美国社会保障体系;第二个时代为可编程计算时代(Programming Computing),兴起于20 世纪40 年代,支持内容从太空探索到互联网都包括其中;第三个时代是认知计算时代(Cognitive Computing),与前两个时代有着根本性的差异。认知系统会从自身与数据、与人的交互中学习,能够不断自我提高,故此认知系统绝不会过时,它们只会随着时间推移而变得更加智能、更加宝贵。这是计算史上重大的理念革命,随着时间推移,认知技术可能会融入许多IT 解决方案和人类设计的系统之中,赋予它一种思考能力。这些新功能将支持个人和组织完成以前无法完成的事情,比如更深入地理解世界的运转方式、预测行为的后果并制定更好的决策。
虽然认知计算包括部分人工智能领域的元素,但是它涉及的范围更广。认知计算不是要生产出代替人类进行思考的机器,而是要放大人类智能,帮助人类更好地思考。认知计算与人工智能一个偏向于技术体系,另一个偏向于最终的应用形态。认知计算的渗透让更多产品与服务具备了智能,认知计算本身也是在向人脑致敬,所以双方不仅不矛盾,反而相辅相成。长期以来人工智能研究者都在开发旨在提升计算机性能的技术,这些技术能让计算机完成非常广泛的任务,而这些任务在过去被认为只有人才能完成,包括玩游戏、识别人脸和语音、在不确定的情况下做出决策、学习和翻译语言。
2、Watson
IBM Watson是认知计算系统的技术平台,这一平台使用一种全新的计算模式,涵盖了信息分析、自然语言处理和机器学习领域的技术创新,能够助力决策者从大量结构化和非结构化数据中揭示潜在规律。
Watson的“认知计算”模式具体包括三个方面:理解、推理、学习。理解:能“理解”人类是Watson能进行认知协作的第一步,主要运用计算系统处理结构化和非结构化数据的能力。推理:Watson主要运用一种名为“假设生成”的算法,能从数据中抽丝剥茧,寻找事物间的相关联系。学习:Watson从大数据中提取关键信息,以证据为基础进行学习。根据上述三步,Watson就能“以不变应万变”,改变商业解决的方式并以此提升效率。基于对自然语言的了解和解构,认知计算能够有针对性地在各个领域进行深入的研究分析,如医疗、金融、安全等方面,帮助用户解决工作中的实际问题。对于企业来说,认知商业可以从非结构化的数据中进行挖掘,推动产品的服务质量,甚至能够在研究领域有所拓展。Watson已经推出了多个应用工具,但本文主要考虑自动客服部分,也就是Watson Engagement Adviser,这是一个通过对话不断进行学习的系统。Watson可以自动选择和优化机器学习算法和模型,整个过程无需人工介入,无需编程,消除了人工智能和大数据分析的一个关键瓶颈。IBM与数千名医疗、法律、金融等领域的专家和专业机构合作,为二十多个行业建立了知识本体。Watson通过阅读和分析海量的专业文献和数据来进行知识吸收、展现和推理,建立证据库,并与领域专家交互合作,增强知识本体,扩充和改进证据库,迅速成为该领域的顶级专家。这二十多个行业本体,是Watson成为认知计算平台的基础。例如在医学上Watson最热门的应用是在癌症诊断治疗的辅助领域,Watson曾经只用17秒的时间就查阅了3469本教科书、69个治疗大纲、247760本专业期刊文献、61540个临床实验数据以及其他106054篇临床医学文献,为一个亚裔癌症患者提出了3个治疗方案,这样的数据处理能力是任何一个人类医生都没办法实现的。
当一个客户提问时,第一步是问题输入(Question in),输入后接着对问题进行分析 (Question Analysis),主要目的是让计算机理解这个问题什么意思、我们在找什么、还存在其他有效信息么、问题中有没有词语提到问题中的其他词语等一系列问题。在这一环节,Watson尝试去理解问题,搞清楚问题到底在问什么,同时做一些初步分析来决定选择哪种方法去应对这个问题。接下来进行初步搜索(Primary Search),看看在数据库中能不能找到或许跟这个问题有关的文件?找到了多少文件?这些文件从哪里来的?搜索结果处理并生成备选答案 (Search Result Processing and Candidate Answer Generation)。在这些文件中有这个问题可能的答案么?有多少个备选答案?
接着是非常关键的一步,即上下文无关回答得分(Context-Independent Answer Scoring) ,根据语境上下文判断答案是否正确,这个选择有可能是正确的答案吗?这个选择是正确的答案形式吗?然后以软滤波(Soft Filtering)来判断有哪些选择是明显错误的?如果是的话,能不能让它们在后面的处理过程中不占太多的时间?到了这一步,每个可能的回答都被给定一个分数,给出这个证据对备选答案支持得到底有多好,并随之进行支持证据检索(Supporting Evidence Retrieval),能在数据库中找到任何能够证明某个选择答案是正确的信息吗?对每个选择来说有多少信息在哪?完成搜索后进行搜索结果处理和上下文相关得分
(Search Result Processing and Context Dependent Scoring),选择工作作为问题回答怎么样?现在有更多的信息,能给每个选择什么分数?
最终对潜在答案列表进行合并,然后对答案进行排名(Final Merging and Ranking),此时Watson会最后问一次还有任何能够改变分数的额外信息吗?每个选择的总分是多少?哪个选择分数最高?分数第二高的选择是什么?最后输出答案(Answer out),返回最高分的答案给客户,然后根据反馈进行尝试判断,从它做的正确(或者错误)中进行学习。
二、智能客服系统的应用
由于专业分工不同,一些科技公司专注于自己的专业领域,如存储、图像识别、随机数生成、验证码发放等核心功能,并将这些功能作为开放的应用接口(API)发布在公网上,各个企业只需要调用即可享受这一类的专业服务而无需自行开发,这使得对于专业技术领域的远程调用架构越来越多地成为了主流。一个典型的远程调用架构如图1所示:

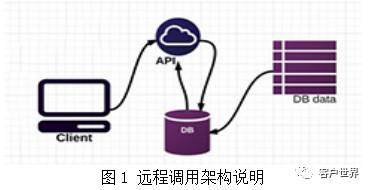
客户打开企业的客服页面或者打开企业的APP之后他们的提问会被转发至远程API并等待远程API的响应,再将响应结果提供给客户,然后等待第二次交互,这就是一种典型的远程调用架构,这一架构使得企业在进行应用开发时变得简单直接,按照这种思路进行设计的智能客服应用架构如图2:
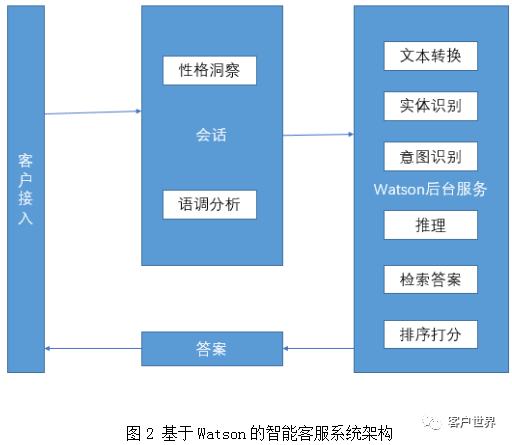
在这样的智能客服系统中,客户接入由企业自行开发的接口开始进行会话,客户提出一个问题后首先根据客户的问题对其进行性格洞察和语调分析,并将会话内容向后传递至Watson获取响应内容,再将响应内容反馈给客户。这样的好处是对于企业的智能客服而言无需关心复杂的Watson后台服务,只需要做好会话、语调分析和客户洞察这三个部分即可,下面逐一介绍这三个核心组件的使用。
笔者注册了Bluemix和Watson Developer并下载了WatsonSDK3.5.3版本,后续内容均以这个版本为准。Watson提供了简单易用的restful风格的API,以JSON格式传输交互数据,通过“调用—返回”这一形式进行交互。对于一般企业应用来说,我们不需要关心Answer Retrieval和AlchemyLanguage一类的深层组件;对一个智能客服系统而言,直接需要依赖的主要有3个组件:Tone Analyzer、Personality Insights、Conversation。下文以Python为例介绍各个组件的使用。
1、声调分析
声调分析组件(Tone Analyzer)用于理解用户语音中的声调和客户说话的风格,调用方法是向Watson提交一段音频或者一段文字,等待分析返回结果。
提交报文:
alchemy_language = AlchemyLanguageV1(api_key=’API_KEY’)
print(json.dumps( alchemy_language.emotion(‘你的音频地址’), indent=2))
返回报文中将告诉我们这段语音中所蕴含的情绪,目前分为anger、disgust,fear、joy、sadness几个大类,一个返回结果的例子如下所示:
{
“status”: “OK”,
“usage”: “By accessing AlchemyAPI or using information generated by AlchemyAPI, you are agreeing to be bound by the AlchemyAPI Terms of Use: http://www.alchemyapi.com/company/terms.html”,
“url”: “http://www.charliechaplin.com/en/synopsis/articles/29-The-Great-Dictator-s-Speech”,
“totalTransactions”: “0”,
“language”: “english”,
“docEmotions”: {
“anger”: “0.639028”,
“disgust”: “0.009711”,
“fear”: “0.037295”,
“joy”: “4e-05”,
“sadness”: “0.002552”
}
}
我们向Watson提交了一段录音,以卓别林在《大独裁者》片中的演讲为例,返回结果告诉我们,根据Watson的分析,这段话中主要的情绪是愤怒(anger),同时混合了少量的恐惧(fear)。
2、个性洞察
个性洞察组件(Personality Insights)用于从文本中挖掘客户的性格,常见的来源是Facebook和twitter,提供一份不大于20M的文本给Watson后它会给出对这个客户的性格分析结果,并给出排行前5名的性格特征。
提交报文:
personality_insights = PersonalityInsightsV3(
version=’2016-10-20′,
username='{username}’,
password='{password}’)
with open(join(dirname(__file__), ‘./profile.json’)) as profile_json:
profile = personality_insights.profile(
profile_json.read(), content_type=’application/json’,
raw_scores=True, consumption_preferences=True)
print(json.dumps(profile, indent=2))
返回报文,为了避免冗余,本文仅展示返回的第一个性格特征。
{
“word_count”: 15223,
“processed_language”: “en”,
“personality”: [
{
“trait_id”: “big5_openness”,
“name”: “Openness”,
“category”: “personality”,
“percentile”: 0.8011555009553,
“raw_score”: 0.77565404255038,
“children”: [
{
“trait_id”: “facet_adventurousness”,
“name”: “Adventurousness”,
“category”: “personality”,
“percentile”: 0.89755869047319,
“raw_score”: 0.54990704031219
},
. . .
]
},
我们向Watson提交一段文本,根据Watson的统计共计包含了15223个单词,根据这段语言的分析,我们可以认为这个人的性格是开放性格——热爱冒险。
3、回话
Conversation回话组件是直接面对客户的一层,客户通过回话组件与客服进行交互,而上述两个组件则是进行辅助理解和精确定位问题用的。在这一组件中我们向Watson提交一段文本,来自客户的输入可以是语音或者文字,Waston识别客户的意图并调用后端组件给出回复。一个典型的例子如下:
{
“input”: {
“text”: “Turn on the lights”
},
“entities”: [
{
“entity”: “appliance”,
“location”: [12, 18],
“value”: “light”
}
],
“intents”: [
{
“intent”: “turn_on”,
“confidence”: 0.8362587462307721
}
],
“output”: {
“log_messages”: [],
“text”: [
“Ok. Turning on the light.”
],
“nodes_visited”: [
“node_1_1467221909631”,
“node_2_1467232480480”
]
}
}
Input部分表示了客户的输入,这个例子中客户输入了turn on the light(打开灯),Watson识别出了这是一个请求(appliance),指向灯(light),目的(intent)是打开它(turn_on),最后给出了输出是Ok. Turning on the light.(好的,正在开灯)。
三、总结与展望
与深度学习为代表的Jimi机器人不同,以认知计算为基础的Watson有了更为明显的进步。笔者在之前的《基于深度学习的自动应答研究》一文中曾经提出以过,对于一些问题尤其是需要复杂上下文推理的问题,自动应答的表现还远远不尽如人意,这首先是由于深度学习为代表的自动应答本质依然是一个分类系统,目标是将大量的问题映射到少量的回答上,这种单一算法为支撑的体系不能处理需要推理和上下文语意环境才能理解的问题。然而以认知计算为基础的Watson则整合了对客户的理解——基于社交网络和公开数据的对客户的情感分析和基于本体的语义推理,在整合这一切之后便有理由认为基于Watson的自动客服会表现得更好,从而将人工客服从处理简单问题的重复劳动中解放出来。
然而在我们进行实证研究中发现Watson在我国的应用中有着自己的缺陷,主要是针对中国市场环境的水土不服。它对客户的理解和掌握主要通过社交网络即Facebook和twitter来实现,但我们期待的其实是一家中国的Watson,整合支付宝或者微信的个人数据形成对客户的理解——这也许是未来最大的障碍,毕竟Facebook和twitter是半公开数据,而微信和支付宝都是核心隐私。此外Watson依旧以英文支持为主,对中文的语义理解还有改进的空间,但毕竟认知计算这一技术正在驱动生活逐步向前,而我们能做的就是努力适应、包容和迎接新的变化。
本文刊载于《客户世界》2017年5月刊;作者吴凡、臧其事,作者单位为中国农业银行上海客服分中心客服一部。
转载请注明来源:认知计算下的智能客服——基于IBM Watson的应用研究
panjl
《客户世界》杂志编辑。有关投稿,呼叫中心企业培训,会议等咨询。可添加编辑潘老师微信:18710108460 或者扫描左边微信二维码进行咨询!

噢!评论已关闭。